Generate your key here https://aistudio.google.com/app/apikeyand enter it into the IDE.
As URL enter: https://generativelanguage.googleapis.com/v1
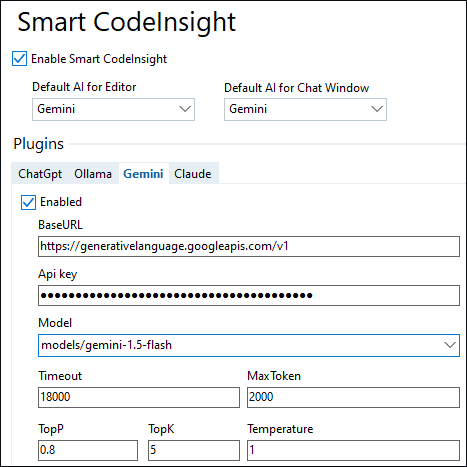
Parameters
Top-P
[official documentation]
Top-P changes how the model selects tokens for output. Tokens are selected from the most (see top-K) to least probable until the sum of their probabilities equals the top-P value. For example, if tokens A, B, and C have a probability of 0.3, 0.2, and 0.1 and the top-P value is 0.5, then the model will select either A or B as the next token by using temperature and excludes C as a candidate. [official documentation]
Lower = less random responses
Higher = more random responses.
Default seems to be 0.5?
Top-K
[generic documentation]
Example: On burgers, I like to add…..
With a Top K of “2”, the LLM would only consider the two most likely tokens, such as ketchup (0.2) and mustard (0.1) . There’s a long-tail of other considerations, such as onion(0.05), pickles(0.04), or butter(0.02), but those would be cropped from consideration.
Grok says that the default value for Gemini is 32!
Temperature
[official documentation]
Lower = Accurate, less creative responses. (Zero = responses for a given prompt are mostly deterministic, but a small amount of variation is still possible.)
Higher = more diverse or creative responses.
Default: 1
Hints:
If the model returns a response that’s too generic, too short, or the model gives a fallback response, try increasing the temperature.
Max output tokens
[official documentation]
Tokens can be single characters like z or whole words like cat. Long words are broken up into several tokens. The set of all tokens used by the model is called the vocabulary, and the process of splitting text into tokens is called tokenization.
Maximum number of tokens that can be generated in the response. A token is approximately four characters.
100 tokens correspond to roughly 60-80 words.
I recommend 2000 (anything between 1000 and 10000 depending on how long your piece of code it).
For example , this piece of code has 260 chars, which means about 65 tokens:
function IntToBin(CONST IntNumber, Digits: Integer): string;
begin
if Digits= 0
then Result:= ''
else
if (IntNumber AND (1 SHL (Digits-1)))>0
then result:='1'+IntToBin(IntNumber, Digits-1)
else result:='0'+IntToBin(IntNumber, Digits-1)
end;TimeOut
At least 30 seconds for small answer.
At least 3 minutes if you want to generate a whole Delphi unit.
The value is in milliseconds! So enter 60000 for 60 seconds.
Feature request
We need to edit all these values dynamically, based on the question we ask. For example, if we want to generate a small routine that we know exactly what it does, we need small values.
But if we design something bigger and we don’t know exactly what we want (creative mode), we need to increase the values.
Troubleshooting
To test if the connection works you can use this script:
prompt $g
cls
curl --ssl-revoke-best-effort "https://generativelanguage.googleapis.com/v1beta/models/gemini-1.5-flash-latest:generateContent?key=YOUR_KEY" ^
-H "Content-Type: application/json" ^
-X POST ^
-d "{\"contents\": [{\"parts\":[{\"text\": \"Explain how AI works\"}]}]}"
pauseEverything went fine, and I got an answer to the “Explain how AI works” question from the AI.
To view the real-time server response/traffic see: https://console.cloud.google.com/apis/api/generativelanguage.googleapis.com/metrics?project=gen-lang-client-0455224601
Problem 1:
Don’t enter the full URL as instructed by Google: https://generativelanguage.googleapis.com/v1beta/models/gemini-1.5-flash-latest:generateContent , because you will get an error like this:

Problem 2:
____________________________________________________________
Related links: